How We Are Training Our AgrisolarAI Model
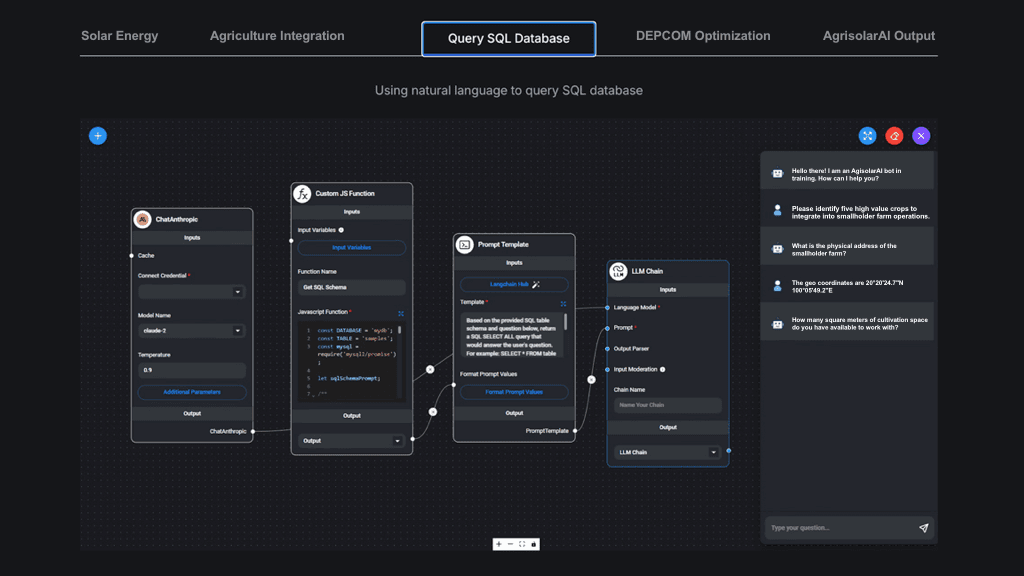
A recent deep dive into building large language models (LLMs) has provided valuable insights that we are applying to the development of our AgrisolarAI model. This article outlines how we are customizing AgrisolarAI using OpenAI’s API, focusing on the practical aspects of training and optimizing the model for agrivoltaic applications.
The Five Major Components of Building AgrisolarAI
- Architecture
- Training Algorithm/Loss
- Data
- Evaluation
- System
While the architecture and training algorithms are foundational, our focus lies on the last three components—data, evaluation, and system—which are critical for deploying AgrisolarAI in real-world scenarios.
Understanding Language Modeling in AgrisolarAI
Language models predict the probability of sequences of words, helping determine the most natural and contextually appropriate sentences. For AgrisolarAI, this means understanding and generating content related to agrivoltaics, such as optimizing land use for both agriculture and solar energy production.
Autoregressive Models in AgrisolarAI
AgrisolarAI employs autoregressive language models that predict each word in a sequence by considering all previous words. This approach allows the model to generate coherent and context-specific responses, essential for addressing complex agrisolar queries.
Cross-Entropy Loss and Tokenization
Cross-Entropy Loss
One of the core concepts in training AgrisolarAI is cross-entropy loss, which measures how well the model’s predictions align with actual data. Lower cross-entropy indicates better performance, guiding us in fine-tuning the model for optimal accuracy.
Tokenization Specific to AgrisolarAI
Tokenization involves breaking down text into tokens, which can be words or sub-word units. For AgrisolarAI, we utilize domain-specific tokenization to capture essential terminology in agrivoltaics. This ensures that the model accurately understands and generates technical terms like “photovoltaic efficiency” or “crop yield optimization.”
Byte-Pair Encoding (BPE)
We use Byte-Pair Encoding (BPE) as our tokenization technique:
- Corpus Preparation: We compile a large corpus of agrivoltaic literature and data.
- Initial Tokenization: Start with one token per character.
- Token Merging: Merge the most common pairs of tokens to form meaningful units.
- Vocabulary Finalization: Repeat until we reach the desired vocabulary size, capturing all essential agrisolar terms.
Evaluation of AgrisolarAI
Perplexity and Domain-Specific Benchmarks
Evaluating AgrisolarAI is crucial for understanding its performance in agrivoltaic contexts.
- Perplexity: Measures the model’s confidence in predicting the next word. A lower perplexity indicates higher certainty and better performance.
- Domain-Specific Benchmarks: We have developed custom benchmarks that assess the model’s ability to handle agrisolar-specific tasks, such as optimizing crop placement under solar panels or predicting energy yields.
Data for Training AgrisolarAI
Data Collection and Curation
Training AgrisolarAI requires high-quality, domain-specific data.
- Academic Journals: We source data from reputable agrivoltaic research papers.
- Industry Reports: Include insights from industry leaders in solar energy and agriculture.
- Government Databases: Utilize agricultural and energy data for real-world applicability.
Data Filtering
We employ rigorous data filtering to ensure:
- Relevance: Only include data pertinent to agrivoltaics.
- Quality: Exclude low-quality or irrelevant information.
- Diversity: Ensure a broad range of scenarios and conditions are represented.
Scaling Laws and Optimizing AgrisolarAI Training
Understanding scaling laws helps us optimize the balance between compute resources, data size, and model parameters.
- Compute Efficiency: We leverage OpenAI’s API to maximize computational efficiency.
- Data Scaling: Incrementally increase data size to observe performance improvements.
- Model Parameters: Adjust the number of parameters to find the optimal model complexity.
Training State-of-the-Art Models for AgrisolarAI
Training a state-of-the-art model like AgrisolarAI involves significant resources.
- Compute Resources: Utilize cloud-based GPUs to handle intensive computations.
- Cost Management: Optimize training processes to reduce costs without compromising performance.
- Benchmarking: Regularly assess the model against both general and domain-specific metrics.
Post-Training and Fine-Tuning for AgrisolarAI
Supervised Fine-Tuning (SFT)
We employ Supervised Fine-Tuning (SFT) to tailor AgrisolarAI to specific agrivoltaic tasks.
- Data Collection: Gather question-answer pairs relevant to agrisolar applications.
- Fine-Tuning Process: Use these pairs to fine-tune the pre-trained model, enhancing its domain-specific performance.
Scaling Data Collection with LLMs
To overcome the challenges of manual data collection:
- LLM Assistance: Use large language models to generate additional training data.
- Quality Assurance: Implement validation steps to ensure the generated data meets our quality standards.
Reinforcement Learning from Human Feedback (RLHF) in AgrisolarAI
We incorporate Reinforcement Learning from Human Feedback (RLHF) to optimize the model based on user preferences.
- Human Evaluators: Experts compare model-generated answers to determine the better response.
- Reinforcement Learning: Use this feedback to adjust the model’s parameters, enhancing its ability to provide preferred responses.
Summary
Building AgrisolarAI is a complex but rewarding endeavor that combines advanced language modeling techniques with domain-specific expertise. By focusing on data quality, model evaluation, and fine-tuning processes, we aim to create a powerful tool that advances the field of agrivoltaics.
By integrating cutting-edge AI technologies with specialized agrisolar knowledge, AgrisolarAI is set to become an invaluable resource for researchers, farmers, and policymakers alike.
o1